
یک پراکسی سرور، کامپیوتری است که بین کلاینت و سرور قرار می گیرد. منظور از کلاینت کامپیوتری است که درخواست یک صفحه وب را داده و سرور هم کامپیوتری است که صفحه وبِ مورد نظر در آن نگهداری می شود. وقتی ما یک صفحه وب را از یک وبسرور درخواست می کنیم، پراکسی سرور ارتباط ما را می دزدد و خودش را به عنوان یک کلاینت جا زده و اطلاعات را از طرف ما از وبسرور درخواست می کند. اگر جوابی دریافت کرد، آن را به ما برمی گرداند، انگار که ما با وبسرور ارتباط برقرار کرده ایم.
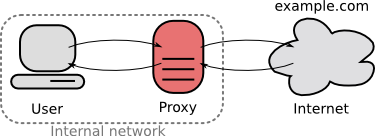
در حالت پیچیدهتر، یک پراکسی سرور می تواند درخواست ها را بر اساس قوانین مختلفی فیلتر کند. یعنی وقتی که یک درخواست دریافت کرد، آن را با قوانینی از پیش تعریف شده مطابقت می دهد، اگر آن قوانین درخواست را تأیید کردند، درخواست را عبور می دهد در غیر این صورت درخواست را به دور خواهد انداخت. این قوانین معمولاً بر اساس آدرس IP کلاینت یا سرور، پروتکل، محتوای یک صفحه وب و … هستند.
به صورت پیش فرض، تمام کلاینت ها از وجود پراکسی سرور آگاه هستند و می دانند که در بین آنها و وبسرور یک واسطه قرار دارد. به همین دلیل باید مشخصات پراکسی سرور بر روی تمام کلاینت ها تنظیم شود. اگر تعداد کلاینت ها زیاد باشد، ممکن است تنظیم پراکسی بر روی تک تک کلاینت ها کاری سخت به نظر برسد. برای رفع این مشکل، پراکسی شفاف یا به انگلیسی intercept و transparent به وجود آمد. در این روش کلاینت ها از وجود پراکسی سرور اطلاعی ندارند و نیازی به تنظیم آن بر روی کلاینت ها نیست.
squid، یکی از قدرتمندترین پراکسیسرورهاست که تحت سیستمعاملهای مختلفی از جمله FreeBSD قابل نصب است.
دلایل استفاده از پراکسیسرور
- صرفه جویی در مصرف پهنای باند
- بالا بردن زمان بارگذاری صفحات وب با کش کردن آنها
- کنترل دسترسی به شبکه
- تقویت کردن یک وب سرور ضعیف
- توزیع بار بین وبسرورهای مختلف برای کاهش بار زیاد بر روی یک وبسرور
- بالا بردن امنیت کاربر از طریق اتصال غیر مستقیم آن به اینترنت
- فیلتر کردن محتوا برای جلوگیری از حمله یک ویروس یا بدافزار
- متعادل کردن بار شبکه از طریق چند اتصال اینترنت
- گزارش گیری از فعالیتهای کاربر
نصب squid
نصب اسکوئید در FreeBSD به دو صورت امکانپذیر است: پورت ها و بسته ها. برای نصب از طریق پورت ها، دستورات زیر را اجرا کنید.
$ cd /usr/ports/www/squid31 $ make install clean
بعد از اجرای دستورات بالا، منویی باز شده و از شما میخواهد تا گزینههای دلخواه خود را برای پیکربندی اسکوئید انتخاب کنید.
پیکربندی squid
در این قسمت به تنظیمات اولیه سرور squid می پردازیم. اولین قدم تخصیص یک نام به visible_hostname در فایل پیکربندی squid میباشد.
فایل تنظیمات اصلی squid در مسیر زیر قرار دارد:
/usr/local/etc/squid/squid.conf
البته این فایل به صورت read-only قرار دارد. برای ویرایش آن باید مجوز نوشتن به آن اضافه کنید:
chmod u+w /usr/local/etc/rc.d/squid/squid.conf
فایل squid.conf را با ویرایشگر دلخواه خود باز نموده و متغیر visible_hostname را با یک نام مناسب جایگزین میکنیم. برای مثال:
visible_hostname myserver
حالا برای اینكه squid آماده راهاندازی شود دستور زیر را اجرا می كنیم:
$ squid -z
دستور بالا دایرکتوری cache را ایجاد خواهد کرد.
مرحله سوم: راهاندازی و متوقف كردن سرور squid
خط زیر را به فایل /etc/rc.conf اضافه کنید:
squid_enable="YES"
سپس برنامه را راهاندازی می کنیم:
/usr/local/etc/rc.d/squid start
و برای متوقف كردن سرور نیز از دستور زیر استفاده می كنیم:
/usr/local/etc/rc.d/squid stop
تنظیم کلاینت ها
از آنجایی كه squid به طور پیش فرض روی پورت ۳۱۲۸ بر روی پروتكل TCP به ترافیك گوش میدهد، ما باید مرورگرمان را به صورت زیر تنظیم كنیم:
Server Address : Squid Server IP Address Port : ۳۱۲۸
این تنظیمات باید بر روی تمام کلاینت ها انجام گیرد.
بررسی فایل پیکربندی
http_port
این گزینه مشخص میکند که اسکوئید باید بر روی چه پورت یا پورتهایی به درخواستها گوش دهد. مقدار پیش فرض ۳۱۲۸ می باشد. البته ما می توانیم از چندین پورت نیز استفاده کنیم. اگر از پروکسی سرور به عنوان وب سرور نیز استفاده می شود پورت ۸۰ را نیز قرار می دهیم و یا اگر سیستم شما چند IP دارد و می خواهید به یک رنج گوش دهد به این صورت عمل می کنید:
http_port 8080 3128 http_port 80 3128 http_port 45.58.69.8 3128
در نسخه های جدیدتر، می توانید حالت عملکرد اسکوئید را هم مشخص کنید. یکی از روش های اجرای اسکوئید روش intercept است که در این روش می توان به درخواست های کلاینت ها بدون نیاز به تنظیم آنها گوش کرد.
برای قرار دادن اسکوئید در این حالت میتوانید به صورت زیر عمل کنید:
http_port 3128 intercept
icp_port
مخفف Internet Cache Portocol می باشد که از این برچسب به این منظور استفاده می شود که بخواهیم چند کش سرور را به هم متصل نمایم تا از اطلاعات همدیگر استفاده نمایند که پورت پیش فرض آن ۳۱۳۰ می باشد:
icp_port 3130
این کش سرورها توسط دایرکتیو cache_peer به یکدیگر متصل میشوند.
cache_peer
دایرکتیو cache_peer برای خبر دادن در مورد کش های همسایه به اسکوئید استفاده می شود. نگاه سریعی به این دایرکتیو داریم:
cache_peer HOSTNAME_OR_IP_ADDRESS TYPE PROXY_PORT ICP_PORT [OPTIONS]
در این کد HOSTNAME_OR_IP_ADDRESS همان IP یا hostname کش مورد نظر است. TYPE مشخص کننده نوع پراکسی سرور است یعنی اسکوئید ما چگونه از آن پراکسی سرور استفاده کند. اسکوئید ما می تواند از پراکسی سرورهای دیگر به عنوان والد (parent) خواهر (siblibg) یا یک عضو از گروه multicast، استفاده کند.
حال بیایید پراکسی سروری با آدرس parent.example.com که قرار است اسکوئید از آن به عنوان پراکسی والد استفاده کند را اضافه کنیم:
cache_peer parent.example.com parent 3128 3130 default proxy-only
پورت ۳۱۳۰، پورت استاندارد icp است. در صورتی که پراکسی مورد نظر از پورت استاندارد استفاده نمی کند، آن را متناسب با پورت صحیح تنظیم کنید. گزینه default مشخص می کند که در صورتی که ارتباط با دیگر کش سرورها میسر نبود، از این کش سرور به عنوان پیش فرض استفاده کن. گزینه proxy-only هم مشخص می کند که اشیائی که از این کش سرور گرفته می شود، به صورت محلی ذخیره نشود. برای مواقعی است که نمی خواهیم در شبکه مان کش سرورها اطلاعات تکراری داشته باشند و آنها را از طریق یک خط پرسرعت به هم وصل کرده ایم.
cache_peer 217.218.155.147 parent 3128 3130 cache_peer 214.215.155.14 sibling 3128 3130
hierarchy_stoplist
این دایرکتیو شکل سادهای داشته و از ارسال درخواست ها به کش سرورهای همسایه جلوگیری می کند. سینتکس این دایرکتیو به شکل زیر است:
hierarchy_stoplist word1 word2 word3 ...
اگر هر یک از کلمات بالا در url یک درخواست وجود داشته باشند، آن درخواست به کش سرورهای همسایه فرستاده نخواهد شد و این گونه درخواست ها مستقیماً به وب سرور ارسال می شوند. این دایرکتیو برای اداره کردن صفحات پویا مفید بوده و می توان این گونه صفحات را در عوض ارسال به یک پراکسی سرور، مستقیا به وب سرور ارسال کرد.
hierarchy_stoplist cgi-bin jsp ?
کد بالا، تمام url هایی که حاوی کلمات cgi-bin ، jsp یا ؟ هستند را مستقیماً به وب سرور ارسال می کند.
acl QUERY urlpath_regex cgi-bin \? no_cache deny QUERY
این دو خط هم از برچسب های مهم Squid هستند که به این منظور استفاده میشوند که پوشه cgi-bin و آدرس بعد این پوشه \? به هیچ وجه کش نشود.
پوشه cgi-bin فایلهای با پسوند *.cgi را دارد که این فایل ها مانند سایت Dynamic می باشند و بهتر است هیچ وقت کش نشوند چون اطلاعات این فایل ها همیشه تغییر می کند این آدرس داخل فایل squid.conf قرار ندهید این مثال از cgi-bin می باشد.
پیش فرض همین برچسب ها خودشان می باشد.
acl QUERY urlpath_regex cgi-bin \? no_cache deny QUERY
cache_mem
اسکوئید برای کش کردن اشیا هم از حافظه RAM و هم از هارد دیسک استفاده میکند. به همین دلیل ما باید قسمتی از حافظه RAM را برای انجام این کار در اختیار اسکوئید قرار دهیم. میتوانید یک چهارم از حافظه RAM خود را برای این کار در نظر بگیرید.
cache_mem 64 MB
maximum_object_size_in_memory
از آنجا که ظرفیت RAM محدود است، باید از آن به طور بهینه و از راه درست استفاده کنیم. اسکوئید قابلیتی دارد که به کمک آن می توانیم مشخص کنیم که حداکثر اندازه اشیاء برای ذخیره در RAM چقدر باشد. اشیاء بزرگتر از این مقدار در RAM قرار نخواهند گرفت. باید سعی کنیم این مقدار را کوچک تنظیم کنیم، چون اگر آن را بزرگ در نظر بگیریم، اشیاء کمی در RAM قرار می گیرند و نرخ HIT (وجود داشتن یک شئ در کش) پایین می آید. مثلاً اگر اندازه کشِ حافظه ۱۰۰ مگابایت باشد و ما بزرگترین اندازه شی در حافظه را ۱۰ مگابایت در نظر بگیریم، فقط ۱۰ شی می تواند در RAM قرار گیرد.
maximum_object_size_in_memory 1 MB
minimum_object_size و maximum_object_size
یکی از مهمترین کارهایی که می توانیم برای بدست آوردن نرخ HIT بهتر انجام دهیم این است که بر روی حجم فایل هایی که قرار است کش شوند محدودیت اعمال کنیم. مثلاً بگوییم فایل هایی که حجمشان بیشتر از ۱ مگابایت است را کش نکن یا اینکه اگر فایلی کمتر از ۱۰ کیلوبایت حجم دارد را در کش قرار نده. بدین ترتیب فقط فایل هایی کش خواهند شد که حجمشان از ۱۰ کیلوبایت بیشتر و از ۱ مگابایت کمتر باشد. مشخص کردنِ این مقدارِِ کمترین و بیشترین بستگی به اندازه دایرکتوری کش دارد.
برای مثال اگر یک دایرکتوری کش با حجم ۱۰GB داریم، و حداکثر اندازه اشیای قابل کش را ۵۰۰ مگابایت تنظیم کنیم، اشیای کمی در کش قرار خواند گرفت و نرخ HIT بسیار پایین می آید. با این حال این مقدار را نباید خیلی پایین تنظیم کنیم چون در این صورت عملیات I/O زیاد میشود ولی میزان صرفه جویی در پهنای باند اندک است. اسکوئید دو دایرکتیو به نامهای minimum_object_size و maximum_object_size تهیه کرده که با آنها میتوانیم بر روی حجم اشیاء محدودیت اعمال کنیم. به طور پیش فرض، پایین ترین اندازه ۰KB است. یعنی اینکه کوچترین اندازه اشیاء هیچ محدودیتی ندارد و حتی کوچکترین فایل ها هم کش خواهند شد. اگر فضای ذخیرهسازی زیادی داریم، می توانیم حدااکثر اندازه را چیزی در حدود ۱۰۰ مگابایت تنظیم کنیم تا مطمئن شویم نرمافزارهای محبوب، آهنگها، ویدئوها و … هم کش میشوند و در مصرف پهنای باند بیشتر صرفه جویی می شود.
minimum_object_size 0 KB maximum_object_size 96 MB
این پیکربندی پایین ترین اندازه و بالاترین اندازه اشیاء را به ترتیب ۰ کیلوبایت و ۹۶ مگابایت درنظر می گیرد. در نتیجه اشیائی که بیشتر از ۹۶ مگابایت حجم داشته باشند، کش نخواهند شد.
cache_dir
با استفاده از دایرکتیو cahce_dir می توان مکانی را برای ذخیرهسازی اشیاء در هارد دیسک مشخص کرد. از این دایرکتیو می توانید چند بار استفاده کنید و به این ترتیب مکان های مختلفی را برای کش کردن اشیاء اختصاص دهید.
cache_dir STORAGE_TYPE DIRECTORY SIZE_IN_Mbytes L1 L2 [OPTIONS]
فیلد STORAGE_TYPE نحوه ذخیره و بازیابی اطلاعات بر روی دیسک را مشخص میکند و میتواند یکی از مقادیر زیر را بگیرد:
ufs: سادهترین روش ذخیره و بازیابی است. اشکال عمده این روش این است عمل I/O توسط پروسه اصلی اسکوئید انجام میشود و به همین دلیل در هنگام انجام عمل I/O، پروسه اسکوئید به حالت blocked می رود. وقتی که پروسه اصلی اسکوئید به حالت blocked رفت، قادر به انجام هیچ کاری نیست و تمام درخواست های رسیده معلق خواهند ماند که در زیر ترافیک سنگین باعث افت شدید کارآیی میشود.
aufs: این روش کارآیی بهتری نسبت به ufs دارد. حرف a به معنی asynchronous است. aufs همان ufs است ولی عمل I/O را به صورت ناهمزمان انجام می دهد. در حالت aufs پروسه اصلی اسکوئید شروع به ایجاد thread هایی کرده و این thread ها را مسئول انجام عمل I/O می کند. اگر یکی از این thread ها بلوکه شود، خللی در کار اسکوئید ایجاد نمی شود و اسکوئید می تواند به درخواست های دیگر رسیدگی کند. بنابراین اگر سیستم عامل ما از کتابخانههای pthread پشتیبانی می کند، همیشه باید از aufs به جای ufs استفاده کنیم مخصوصاً اگر بار سرور زیاد است.
diskd برای انجام عمل I/O، از یک پروسه خارجی و مستقل استفاده می کند. اسکوئید درخواستهایش را از طریق یک صف به disk می فرستد و diskd هم یکی یکی به آنها پاسخ می دهد. چون diskd از یک سیستم صف بندی استفاده می کند، ممکن است در طول زمان و در یک سرور پرترافیک overload شود. بنابراین می توانیم دو پارامتر به دایرکتیو cache_dir اضافه کنیم تا به اسکوئید بگوییم وقتی درخواست های موجود در صف بیشتر از توان diskd بود، چه کاری انجام دهد:
cache_dir diskd DIRECTORY SIZE_Mbytes L1 L2 [OPTIONS] [Q1=n] [Q2=n]
اگر تعداد درخواست های منتظر در صف بیشتر از مقدار Q1 باشد، اسکوئید دیگر درخواست I/O به diskd نمی فرستد. در این حالت هرچند اسکوئید می تواند به طور معمول به درخواست ها رسیدگی کند، ولی قادر به کش کردن اشیاء جدید نیست یا نمی تواند از کش شیئی واکشی کند. در این هنگام، نرخ HIT پایین می آید. مقدار پیش فرض Q1 عدد ۶۴ است. اگر تعداد درخواست های منتظر در صف به مقدار Q2 برسد، اسکوئید از کار کردن بازمیایستد و به حالت blocked می رود. در این حالت به هیچ درخواستی رسیدگی نمی شود تا زمانی که تعداد پیغام های موجود در صف به زیر این عدد بیاید. مقدار پیش فرض Q2 عدد ۷۲ است.
اگر مقدار Q1 بیشتر از Q2 باشد، ممکن است اسکوئید بارها بلوکه شود ولی در این حالت نرخ HIT بهتر است. اگر Q1 کمتر از Q2 باشد، اسکوئید هنوز می تواند به درخواست ها رسیدگی کند و بلوکه نمی شود ولی نرخ HIT پایین می آید.
فیلد DIRECTORY هم مسیر شاخهای که قرار است اشیا در آنجا ذخیره شوند را مشخص میکند.
فیلد SIZE_Mbytes اندازه دایرکتوری کش را تعیین میکند. این اندازه بر حسب مگابایت است. وقتی که حجم دایرکتوری کش به این مقدار رسید، اسکوئید شروع به پاک کردن اشیای قدیمی کرده تا فضا برای ذخیره اشیای جدید فراهم شود.
دو آرگومان به نام های L1 و L2 برای دایرکتیو cache_dir وجود دارد. اسکوئید اشیای قابل کش شدن را در یک ساختار سلسله مراتبی ذخیره می کند تا دسترسی به آن شی راحت تر شود. این ساختار دو سطح دارد. آرگومان L1 تعداد دایرکتوری ها در سطح اول را مشخص می کند. L2 هم مشخص می کند که در هر کدام از دایرکتوری های سطح ۱، چند زیردایرکتوری وجود داشته باشد. مثلا اگر مقدار L1=8 و L2=64 باشد، دایرکتوری ریشه ۸ دایرکتوری خواهد داشت که هر کدام از این ۸ دایرکتوری، خود دارای ۶۴ زیردایرکتوری هستند. باید L1 و L2 را به اندازه کافی بزرگ تنظیم کنیم تا دایرکتوری های سطح دوم حجم انبوهی فایل را دربرنگیرند.
تاکنون با پارامترهای مختلف cache_dir آشنا شدیم. حال بیایید دایرکتوری /squid_cache/ را با ۵۰GB ظرفیت به اسکوئید معرفی کنیم:
cache_dir aufs /squid_cache/ 51200 32 512
در مثال بالا به اسکوئید گفتیم فایلهایت را به روش aufs و در مسیر /squid_cache/ با حجم ۵۱۲۰۰ مگابایت ذخیره کن. اسکوئید تحت دایرکتوری /squid_cache/ سیودو دایرکتوری دیگر می سازد که در هر دایرکتوری ۵۱۲ دایرکتوری دیگر وجود دارد. اگر میانگین هر فایل را ۱۶ کیلوبایت فرض کنیم:
۵۱۲۰۰x1024÷(۳۲x512x16) = 200
در هر دایرکتوری سطح دوم، ۲۰۰ فایل قرار می گیرد که کاملاً مناسب است.
refresh_pattern
از طریق دایرکتیو refresh_pattern می توانیم وضعیت اشیای کش شده را کنترل کنیم.
استفاده از refresh_pattern برای کش کردن پاسخ های غیر قابل کش، می تواند باعث به وجود آمدن برخی رفتارهای غیر منتظرانه شود. از این گزینه با دقت استفاده کنید.
وب سرور به همراه تمام پاسخهای ارسالی، یک هدر به نام http reply header اضافه می کند که این هدر شامل فیلدهایی از قرار زیر است:
Date: نشان دهنده تاریخ ارسال فایل است. یعنی در این تاریخ فایل توسط وب سرور برای اسکوئید ارسال شده است. از این پس این فیلد را OBJ_DATE می نامیم.
Last-Modified: این فیلد نشان دهنده تاریخ آخرین تغییر (یا ایجاد) فایل است. از این پس این فیلد را OBJ_LASTMOD می نامیم.
Expires: این فیلد مشخص کننده تاریخ انقضای فایل است. یعنی از این تاریخ به بعد دیگر فایل قدیمی شده و قابل استفاده نیست. این فیلد اختیاری است یعنی وب سرور می تواند آن را مشخص نکند. اسکوئید از روی این فیلد تشخیص می دهد که یک شی تازه است یا نه. اگر این تاریخ در آینده باشد، فایل تازه است و اگر هم تاریخ این فیلد در گذشته باشد، فایل قدیمی یا به اصطلاح بیات شده است.
می توان گفت که فیلدهای معرفی شده مهمترین فیلدهای یک هدر http هستند. اما چند اصطلاح دیگر را هم با کمک این فیلدها تعریف می کنیم:
object Age یا عمر شئ: مشخص کننده مدت زمانی است که شئ در کش وجود دارد و از فرمول زیر محاسبه می شود:
OBJ_AGE = NOW - OBJ_DATE
LM Age: نشان دهنده عمر شی در هنگام دریافت آن از وب سرور است و از فرمول زیر محاسبه می شود:
LM_AGE = OBJ_DATE - OBJ_LASTMOD
LM-Factor: نسبت object_age به LM_Age را می گویند:
LM_FACTOR = OBJ_AGE / LM_AGE
خب حالا به کمک این تعاریف، نحوه کار با دایرکتیو refresh_pattern را یاد میگیریم. refresh_pattern ها میتوانند با تازه نگه داشتن یک شئِ تاریخ مصرف گذشته (البته برای مدت کوتاهی) یا با خنثی کردن بعضی از هدرهای http باعث بالا رفتن نرخ HIT شوند. refresh_pattern از عبارات باقاعده برای تشخصی فایلها استفاده میکنند. خب بیایید نگاهی به سینتکس دایرکتیو refresh_patter بیندازیم:
refresh_pattern [-i] regex min percent max [OPTIONS]
پارامتر regex باید یک عبارت با قاعده باشد که url درخواستی را توصیف می کند. می توان چند خط refresh_pattern داشت. در این حالت درخواست مورد نظر به ترتیب از بالا به پایین با refresh_pattern ها مقایسه میشود. اولین refrsh_pattern ای که با درخواست تطبیق پیدا کند، بر روی آن اعمال می شود.
به طور پیش فرض regular expression ها به حروف کوچک و بزرگ حساس هستند. برای غیر حساس کردن آنها از -i استفاده کنید.
ممکن است وب سرور تاریخ انقضای بعضی از اشیاء یا پاسخهایی که ارسال می کند را مشخص نکرده باشد. در این صورت با پارامتر min می توان حداقل زمانی (بر حسب دقیقه) که آبجکت باید تازه فرض شود را مشخص کرد. تا زمانی که OBJ_AGE یک شی از این مقدار کمتر باشد، آن شی تازه است. مقدار پیش فرض و توصیه شده برای این پارامتر ۰ است. چون عوض کردن آن ممکن است باعث بوجود آمدن اشکالات غیر منتظرانه ای با سایت های پویا شود. در صورتی که کاملاً مطمئن هستید که وب سایت هیچ محتوای پویایی ندارد، می توانید این مقدار را بیشتر کنید.
پارامتر max حداکثر زمانی را مشخص می کند که شی تازه فرض می شود. یک شی تازه نیست مگر اینکه OBJ_AGE آن از این مقدار کمتر باشد. اگر OBJ_AGE یک شی از این مقدار بیشتر شود، آن شی دیگر تازه نیست.
Lm-factor مشخص کننده تازگی اشیائی است که عمرشان بین min و max باشد. در این مورد اسکوئید LM-factor شی را با پارامتر percent مقایسه می کند. اگر LM-Factor کمتر از percent باشد، شی مورد نظر تازه است.
اسکوئید برای تعیین تازه یا بیات بودن یک شئ از الگوریتم زیر استفاده می کند. مراحل زیر به ترتیب انجام می شوند.
یک شی:
- بیات است اگر تاریخ انقضای آن در گذشته باشد.
- تازه است اگر تاریخ انقضای آن در آینده باشد.
- بیات است اگر OBJ_AGE آن از max بیشتر باشد.
- تازه است اگر lm-factor کمتر از مقدار percent باشد.
- تازه است اگر OBJ_AGE کمتر از min باشد.
- در بقیه حالت ها بیات است.
شبه کد زیر مراحل بالا را به خوبی توصیف می کند:
if (EXPIRES) {
if (EXPIRES <= NOW)
return STALE
else
return FRESH
}
if (OBJ_AGE > CONF_MAX)
return STALE
if (OBJ_DATE > OBJ_LASTMOD) {
if (LM_FACTOR < CONF_PERCENT)
return FRESH
else
return STALE
}
if (OBJ_AGE <= CONF_MIN)
return FRESH
return STALE
با ذکر یک مثال مطالب بالا را روشن می کنیم:
refresh_patten -i ^http://example.com/test.jpg$ 0 60% 1440
{kind=link}
فرض کنید یک کلاینت عکس http://example.com/text.jpg را یک ساعت پیش درخواست کرده است و عکس آخرین بار شش ساعت پیش تغییر کرده است. حالا فرض کنید وب سرور تاریخ انقضای این فایل را مشخص نکرده باشد. تا اینجا ما این مقادیر را داریم:
{kind=link}
LM_AGE: ۶-۱ = ۵ hours OBJ_AGE: ۱ hours lm-factor: ۱÷۵ = ۲۰%
خب بیایید چک کنیم ببینیم که آیا شی تازه است یا نه:
OBJ_AGE شصت دقیقه است و از ۱۴۴۰ بیشتر نیست. پس این نمی تواند عامل تعیین کننده باشد.
Lm-factor مساوی با ۲۰ درصد است و از ۶۰ درصد پایینتر است بنابراین شی تازه است.
حالا بیایید تاریخ انقضای شی را محاسبه کنیم. OBJ_AGE پنج ساعت است و مقدار percent هم ۶۰ است. پس :
(۵ x 60) ÷۱۰۰ = ۳ hours
که چون یک ساعت از آن گذشته تا دو ساعتِ آینده شی مورد نظر تازه است. ما موفق شدیم فرمولی که اسکوئید با آن تازگی یک شی را محاسبه می کند را بیاموزیم!
اسکوئید راهکارهایی فراهم کرده که می توان اجبارا هدر Expires یا دیگر هدرهای مرتبط با کشینگ را نادیده گرفت و آنها را خنثی کرد. این کار را می توان با استفاده از چند گزینه به همراه دایرکتیو refresh_pattern انجام داد. در ادامه نگاهی به این گزینه ها می اندازیم.
لطفاً توجه داشته باشید که استفاده از این گزینه ها باعث میشود تا استاندارد های HTTP نقض شوند و این می تواند باعث به وجود آمدن اشکالاتی در مرور سایت ها شود.
Override-expire
این گزینه باعث میشود تا هدر Expires (که نقش اصلی برای تعیین تازگی یک شی دارد) نادیده گرفته شود. با نادیده گرفتن این هدر، پارامتر های min و max و percent نقشی اساسی برای تعیین تازه یا بیات بودن یک شی بازی می کنند.
Override-lastmod
این گزینه اسکوئید را مجبور به نادیده گرفتن هدر Last-Modified می کند. با نادیده گرفتن این هدر، پارامتر min تعیین کننده تازگی یک شی است. اگر این پارامتر بر روی ۰ تنظیم شده باشد، این گزینه هیچ استفادهای ندارد.
اینها هم refresh_pattern های Microsoft هستند که تغییراتی در آنها داده شده تا درست کار کنند.
refresh_pattern http://*.windowsupdate.microsoft.com/ 0 60% 20160 refresh_pattern http://office.microsoft.com/ 0 60% 20160 refresh_pattern http://windowsupdate.microsoft.com/ 0 60% 20160 refresh_pattern http://wxpsp2.microsoft.com/ 0 60% 20160 refresh_pattern http://xpsp1.microsoft.com/ 0 60% 20160 refresh_pattern http://w2ksp4.microsoft.com/ 0 60% 20160 refresh_pattern http://download.microsoft.com/ 0 60% 20160
Access Control Lists
acl ها یکی از اجزای پایه برای کنترل دسترسی هستند که با دایرکتیوهای دیگری مثل http_access یا icp_access و … ترکیب میشوند. Acl ها وظیفه شناسایی یک درخواست را بر عهده دارند. وقتی که درخواست از طریق acl ها شناسایی شد، می توان با دایرکتیوهایی نظیر http_access یا cache (به این دایرکتیوها access rule میگویند)، تصمیم گرفت که آیا این درخواست مجاز است یا غیر مجاز. این دایرکتیوهایی که وظیفه مجاز بودن یا نبودن یک درخواست را تعیین می کنند، معمولا به _access ختم می شوند. پس تا اینجا یاد گرفتیم که acl ها به تنهایی نمی توانند جلوی دسترسی افراد را بگیرند، آنها فقط یک درخواست را شناسایی می کنند. بر اساس شناسایی که آنها انجام می دهند، می توان با access rule ها عمل واقعی کنترل دسترسی را انجام داد.
Acl ها با کلمه کلیدی acl تعریف می شوند. به دنبال آن یک نام دلخواه برای acl انتخاب کرده وبعد نوع آن acl را مشخص کرده و در آخر مقادیر مخصوص آن acl را بنویسیم. یعنی:
acl ACL_NAME ACL_TYPE value
یک مثال:
acl mylan src 192.168.25.0/24
acl ها انواع مختلفی دارند که در زیر آورده شده است:
| نام | عملکرد |
|---|---|
| src | درخواست ها را بر اساس آدرس IP مبدأ (درخواست دهنده) شناسایی می کند. یعنی کسی که درخواست را ارسال کرده است. |
| dst | درخواست ها را بر اساس IP مقصد یا گیرنده مشخص میکند. یعنی کسی که درخواست برای او ارسال شده است. |
| arp | به کمک این acl می توانید کلاینت ها را بر اساس Mac Address یا همان آدرس سخت افزاریشان شناسایی کنید. |
| myip | عمل شناسایی درخواست ها بر اساس IP ای انجام میشود که اسکوئید از طریق آن IP به درخواست ها رسیدگی می کند. فقط زمانی کاربرد دارد که سرور اسکوئید چند آدرس IP داشته باشد. |
| srcdomain | مشابه src است اما به جای آدرس IP از نام دامنه استفاده میکند. |
| dstdomain | مشابه dst است اما به جای آدرس IP از نام دامنه استفاده میکند. |
| port | هر بار که یک کلاینت درخواستی را ارسال میکند، اسکوئید باید به پورت خاصی بر روی سرور مورد نظر وصل شود. برای مثال اگر کلاینتی درخواست http://example.com بدهد، اسکوئید سعی می کند به پورت ۸۰ روی سرور example.com متصل شود. بنابراین می توانیم از پورت ها برای شناسایی درخواست ها استفاده کنیم. |
| method | تمام درخواست های HTTP با یک متد HTTP همراه هستند. برای مثال وقتی که در address bar مرورگر خود http://example.com را تایپ می کنیم، یک درخواست GET به سرور example.com ارسال می کنیم. همچنین وقتی که یک فرم را پر می کنیم، یک درخواست POST صورت می پذیرد. از متدهای متداول می توان به متدهایPUT, HEAD, CONNECT, TRACE, OPTIONS، DELETE و … اشاره کرد. بنابراین میتوان از طریق متدها هم به شناسایی درخواست ها پرداخت. |
| time | با استفاده از acl های نوع time می توانیم یک دوره زمانی را بر اساس روز یا ساعت مشخص کنیم. سپس تمام درخواست هایی که طی آن دوره زمانی ارسال شوند، توسط acl مورد نظر شناسایی می شوند. قالب این acl به شکل زیر است: |
acl ACL_NAME time [day-abbreviation] [h1:m1-h2:m2]
روزهای هفته با یک علامت اختصاری نشان داده میشوند که در جدول زیر لیست شده است:
| علامت اختصاری | روز | روز به فارسی |
|---|---|---|
| S | Sunday | یکشنبه |
| M | Monday | دوشنبه |
| T | Tuesday | سهشنبه |
| W | Wednesday | چهارشنبه |
| H | Thursday | پنجشنبه |
| F | Friday | جمعه |
| A | Saturday | شنبه |
| D | All Weekdays | تمام روزهای هقته |
پس برای شناسایی تمام درخواست هایی که در روزهای یکشنبه، دوشنبه و سه شنبه ارسال می شوند، باید acl زیر را بنویسیم:
acl days time SMW
روزها را بدون فاصله و کنار هم بنویسید. همچنین در هنگام مشخص کردن ساعت توجه داشته باشید که h1:m1 باید پایینتر از h2:m2 باشد و همین طور ساعت را باید در قالب ۲۴ ساعته بنویسید. بیایید acl هایی برای ساعات کاری یک اداره بنویسیم:
acl morning_hrs time MTWHF 09:00-12:59 acl lunch_hrs time D 13:00-13:59 acl evening_hrs time MTWHF 14:00-18:00
پیشتر آموختیم که acl ها فقط برای شناسایی درخواست ها بر اساس قوانین مختلف هستند. Acl ها توسط خودشان قابل استفاده نیستند. آنها باید توسط دایرکتیوهای کنترل دسترسی یا همان access rule ها ترکیب شوند تا اجازه دسترسی به منابع داده یا گرفته شود. دایرکتیو http_access، یکی از مهمترین این دایرکتیوها است که برای اهدای دسترسی جهت انجام انتقالات HTTP استفاده می شود. یعنی می توان انتقالات HTTP را با این دایرکتیو کنترل کرد. اجازه دهید نگاهی به سینتکس این دایرکتیو بیندازیم:
http_access allow|deny [!]ACL_NAME
با استفاده از این دایرکتیو می توان هم اجازه دسترسی به انتقالات HTTP را داد و هم این اجازه را سلب کرد. در کد بالا ACL_NAME همان درخواستی است که قصد اجازه دادن/ندادن آن را داریم. یک مثال:
acl bad_site dstdomain .example.com http_access deny bad_site
در مثال بالا، ابتدا یک acl با نام bad_site تعریف کردیم. هر درخواستی که بخواهد به example.com برود، توسط این acl شناسایی م یشود. در خط دوم این درخواست های شناسایی شده را deny کردیم. اگر قبل از نام acl علامت تعجب (!) بیاید، دسترسی به درخواست هایی که توسط آن acl شناسایی نشده داده/گرفته می شود.
acl bad_site dstdomain example.com http_access allow !bad_site
کد بالا هم همان نتیجه را دارد و دسترسی به تمام سایت ها غیر از example.com مجاز است.
مثالها:
جلوگیری از دسترسی یک کلاینت خاص:
acl bad_client src 192.168.1.1 http_access deny bad_client
برای رد نمودن ویروس هایی که از CMD برای انتقال استفاده می کنند:
acl VIRCMD urlpath_regex winnt/system32/cmd.exe? http_access deny VIRCMD
برای تعریف یک رنج IP:
acl mynet src 217.218.0.0/24 http_access allow mynet
برای مسدود کردن سایت هایی که حاوی کلمات خاصی هستند:
acl badurl url_regex –i sx http_access deny badurl
برای مسدود کردن پورت هایی که از کش سرور رد می شوند:
acl badports port 7 20 81 http_access deny badports
اجازه دسترسی در زمان خاص (روز-ساعت):
acl shab time 17:00-24:00 http_access allow shab
cache_access_log
cache_store_log
cache_log
این سه برچسب برای گرفتن Log از کارکرد Squid و اینکه کاربران به چه سایتی می روند و کدام Object در حال کش شدن می باشد استفاده میشود. Log ها مقداری از حجم هارد دیسک شما را خواهد گرفت اگر هارد شما حجم کمی دارد بهتر است این Log ها را None کنید تا هارد شما فضای خالی داشته باشد برای none کردن به این شکل عمل می کنیم :
cache_access_log none cache_store_log none cache_log none
و اگر هارد شما فضا زیاد دارد و می خواهید Log داشته باشید به این شکل عمل کنید:
cache_access_log /var/log/squid/access.log cache_store_log /var/log/squid/store.log cache_log /var/log/squid/cache.log
در صورت انجام این کار احتیاج به یک برچسب دیگر دارید به نام
logfile_rotate
که این برچسب بر حسب روزی که مشخص می کنید فایل های Log شما را فشرده کرده تا حجمی که فایل Log می گیرد کم شود. اگر این برچسب گذاشته نشود Squid شما بعد از مدتی به خاطر زیاد شدن Log از اجرا باز میایستد و تا زمانی که Log ها را پاک نکنید اجرا نمی شود.
logfile_rotate 4
ftp_user
برای انتقال فایل ها از سرور FTP که احتیاج به نام کاربر دارند مورد استفاده می شوند که شما می توانید از ایمیل خود یا از کاربر میهمان anonymous استفاده نمایید
ftp_user anonymous@
dns_nameservers
Squid از DNS های که در فایل /etc/resolv.conf تعریف شده، استفاده میکند. شما با این برچسب میتوانید از DNS های دیگر استفاده نمایید
dns_nameservers 192.9.9.3 4.2.2.2
auth_param
از این ابزار برای احزار هویت کاربران استفاده می شود که پیش فرض آن به شکل زیر می باشد
auth_param basic children 5 auth_param basic realm Squid proxy-caching web server auth_param basic credentialsttl 2 hours auth_param basic casesensitive off
به منظور بالا بردن امنیت سرور باید دو برچسب دیگر اضافه کنیم :
authenticate_ttl 1 hour authenticate_ip_ttl 2 seconds
پارامتر authenticate_ttl تعریف کننده این مورد است که تا چه مدت زمان Squid اطلاعات Authenticate کلاینت را به خاطر بسپارد . این تنظیم در واقع کلاینت را وادار مینماید که تا بعد از یک دوره زمانی خود را دوباره Authenticate کند
request_header_max_size
این پارامتر به این منظور مورد استفاده میشود که مقدار اندازه قابل پذیرش HTTP Header را محدود نماید. مقدار پیش فرض در اینجا ۱۰ کیلو بایت بوده که از مقدار منطقی بیشتر به نظر می رسد به این دلیل که سایز متوسط header ۵۱۲ بایت است در صورتی که سنگین ترین header ممکن است در حد کیلوبایت باشند. بیشتر حملات DoS نسبت به پراکسی سرورها اینگونه رخ میدهد که headerهایی برای آنها فرستاده شود که از مقداری که پراکسی سرور میتواند جوابگو باشد بیشتر باشد که شما می توانید مقدار آن را تغییر دهید سعی کنید بیشتر از ۱۰ KB نباشد.
request_header_max_size 8 KB
Time Out
در این قسمت تعدادی برچسب وجود دارد که Time Out آنها در اینجا تعیین می شود که می توانید آنها را به شکل زیر پیکربندی نمایید
negative_ttl 5 minutes positive_dns_ttl 30 minutes negative_dns_ttl 1 minute connect_timeout 1 minute read_timeout 15 minutes request_timeout 5 minutes client_lifetime 14 hours pconn_timeout 120 seconds shutdown_lifetime 10 seconds
در این قسمت به توضیح دو برچسب می پردازیم که از لحاظ امنیتی مهم هستند
برچسب client_lifetime بیشترین زمانی است که کلاینت میتواند به عنوان یک پروسه Squid قرار گرفته باشد. در واقع این تنظیم سرور شما را از باز بودن تعداد زیادی سوکت محافظت مینماید. بستگی به شرایط شما، ممکن است ۸ ساعت مناسب باشد در صورتی که پیش فرض آن ۱ روز کمیزیاد به نظر میرسد. با بررسی وصل شدن کلاینتها میتوان زمان مناسب را تشخیص داد. یک نفوذگر میتواند با استفاده از lifetime طولانی تعداد زیادی سوکت را باز نماید و این خود باعث نوعی حمله DOS میگردد. اما پارامتر pconn_timeout شبیه به client_lifetime میباشد با این تفاوت که فقط شامل ارتباطهای بیکار(Idle Connection) میگردد.
reply_body_max_size
با استفاده از این برچسب می توانید یک رنج را محدود به استفاده از اینترنت نمایید که بر حسب bytes می باشد.
acl net src 192.168.1.0/24 reply_body_max_size 800000000000 allow net
cache_mgr
اگر Squid از کار بیفتد، یک e-mail به آدرس مشخص شده با برچسب cache_mgr ارسال می شود. همچنین این آدرس به انتهای صفحه های خطایی که به کاربران ارسال میشود، اضافه می شود.
cache_mgr ali@elka-teh
با اینکه معمولاً اسکوئید را با کاربر ریشه اجرا می کنیم، اما اسکوئید هرگز با امتیازات این کاربر اجرا نمی شود. اسکوئید به محض اجرا توسط کاربر ریشه، UID و GID خودش را به کاربری که توسط دایرکتیو cache_effective_user مشخص شده تغییر می دهد. یعنی ما اسکوئید را با کاربر root اجرا می کنیم ولی اسکوئید سطح دسترسی خودش را به یک کاربر دیگر کاهش می دهد. علت این کار این است که اگر پروسه اسکوئید مورد حمله قرار بگیرد، مهاجم نتواند هر کاری که خواست انجام دهد.
cache_effective_user squid cache_effective_group squid
اجرای اسکوئید در حالت transparent یا intercept
با اجرا کردن اسکوئید در این حالت، نیازی به تنظیم کلاینت ها نیست. برای انجام این کار خط زیر را به فایل پیکربندی اسکوئید اضافه کنید:
http_port 3128 intercept
در مرحله بعد باید ترافیک وب را به کمک یک برنامه packet filtering به اسکوئید ارسال کنید. ابتدا مطمئن شوید که خط زیر در فایل پیکربندی کرنل وجود دارد:
options IPFIREWALL_FORWARD
این خط در کرنل GENERIC وجود ندارد. بنابراین شما باید این خط را به فایل پیکربندی کرنل اضافه کرده و آن را مجددا کامپایل کنید.
حالا به کمک دستورات زیر ترافیک وب را به اسکوئید هدایت کنید:
ipfw add 100 allow tcp from me to any dst-port 80 keep-state ipfw add 200 forward 127.0.0.1, 3128 tcp from any to any dst-port 80